


Taking the pain out of C2 infrastructure (Part 2)
Modernizing the CIA's operational infrastructure. Multi/Hybrid Cloud Docker Swarm clusters and mesh VPN networks 🐿

After writing Red Baron I came to realize Terraform wasn’t the solution for my Red Team infrastructure woes. It could be part of the solution, but wasn’t the silver-bullet I was hoping for. Through much trial and error I discovered quickly that Terraform works well only when spinning up the same infrastructure over and over again. If you find yourself constantly changing/adapting your infrastructure (which I found myself doing most of the time) Terraform and HCL become cumbersome and don’t necessarily allow you to react quickly to a constantly evolving engagement among a swath of other things.
I also started realizing I was increasingly “starved” for an actual real-life reference model. I read literature on the subject and spoken to a fair amount of people in the industry who deal with offensive infrastructure creation on a daily basis but there are a lot of unspoken nuances.
Additionally, everyone has varying risk tolerances when it comes to OPSEC and the client’s data (inevitably winding up on your infrastructure during post-exploitation and network exfiltration).
What I wanted was a “real-life” reference to understand the big picture. To accomplish this I really only had 3 choices:
join a ransomware gang for a few months
intern at 4 different Red Team consultancies back-to-back
join a three letter government agency
All three of these options kinda sucked. Fortunately, or unfortunately depending on your perspective, the Vault 7 Leaks dropped right about the time I was having this mini crisis. Surely if there was someone to use as a reference when it comes to offensive infrastructure it would probably be the CIA.
The Vault 7 leaks have already been dissected with a fine tooth comb by the Cybersecurity community. However, every 6 months or so I find myself going through all the leaked documents again only to find stuff that I missed. If you’re an offensive security professional and haven’t spent time going through them, just do it. Don’t let your dreams be dreams.
So how does the CIA “do” C&C infrastructure?
They seem to be super fond of TLS as a C2 channel and mTLS to authenticate their implants.
Once a host gets “implanted”, it communicates back to a re-director a.k.a “Listening Post” in spook parlance 👻.
Every “Listening Post” is a public-facing external server and is usually hosted by a shell company disguised as a hosting provider. Multiple shell companies are sometimes created for one operation.
The “Listening Posts” sole purpose is to tunnel the C2 traffic back to a proxy server via a VPN connection.
The proxy server is responsible for filtering out “bad traffic” and maintaining OPSEC
If the requests hitting the proxy authenticate successfully via mTLS they get passed back to the C2 server.
If the requests don’t authenticate successfully, they get passed to a “Cover Server” which is responsible for serving up fake websites.

The above graph makes things a lot easier to visualize although it’s not completely clear the difference in meaning (if any) between the red and blue blocks.
For the VPN tunnels, they seem to use OpenVPN.

Interestingly enough, the “Blot” proxy in the above operational infrastructure diagram seems to be a custom in-house solution which was replaced by Nginx:
“This new infrastructure configuration replaces the Blot proxy with Nginx to provide SSL communication (rather than something that looks like SSL) between the implant and the response servers.”1
This Nginx proxy was later dubbed “Switchblade”.
Shout-out to the one CIA operator who took the time to brainstorm tool names. Kudos sir/madam, my personal favorite is Snooki's Revenge. Whoever you are I owe you a beverage.
Switchbalde gets described as an"… authenticating proxy for operational use with other proxy services such as Hive and Madison. Switchblade employs self-signed public key certificates in conjunction with open-source web server Nginx and Linux IP policy routing to pass authenticated data to a tool handler and unauthenticated data on to a cover server.”2
On page 9 of the Switchblade PDF they document the full Nginx configuration file they use.
Below is their updated architecture graph that replaces the Blot Proxy with Switchblade (notice here they detail the difference between the blue and red blocks):

The exact meaning of “Protected Operational Network” is debatable but I’m interpreting it as on-premise infrastructure. With this setup, the exfiltrated data is always in transit and does not reside on disk until it hits the “Protected Operational Network”.
In the interest of being thorough according to the Amazon Atlas leak:
“Amazon is the leading cloud provider for the United States intelligence community. In 2013, Amazon entered into a $600 million contract with the CIA to build a cloud for use by intelligence agencies working with information classified as Top Secret”
As a consequence, “Protected Operational Network” could also mean the AWS Secret Region 🤷🏻♂️
In any case, this seemed like a really good foundation to build off. Obviously, in a consultancy or internal Red Team scenario we don’t need to go “full CIA” and open shell companies for each re-director (if you do, congrats? call me maybe?).
Armed with this knowledge, a few years pass until I stumble upon Nebula and Tailscale. You can think of Tailscale as a commercial version of Nebula with some major quality-of-life improvements, a nice UI and some architecture enhancements especially when it comes to integrating with authentication and IDP.
If you want an in-depth explanation of how Nebula & Tailscale work take a gander at the following two articles:
TL;DR: Nebula/Tailscale make use of the same protocol as WireGuard and create lightweight VPN tunnels. What makes them stand out is they do away with the “Hub and Spoke” architecture which all traditional VPNs (and WireGuard for that matter) use.

Instead, they create a mesh/overlay network which seamlessly allows each host to communicate directly with each other instead of having to go though a VPN concentrator:
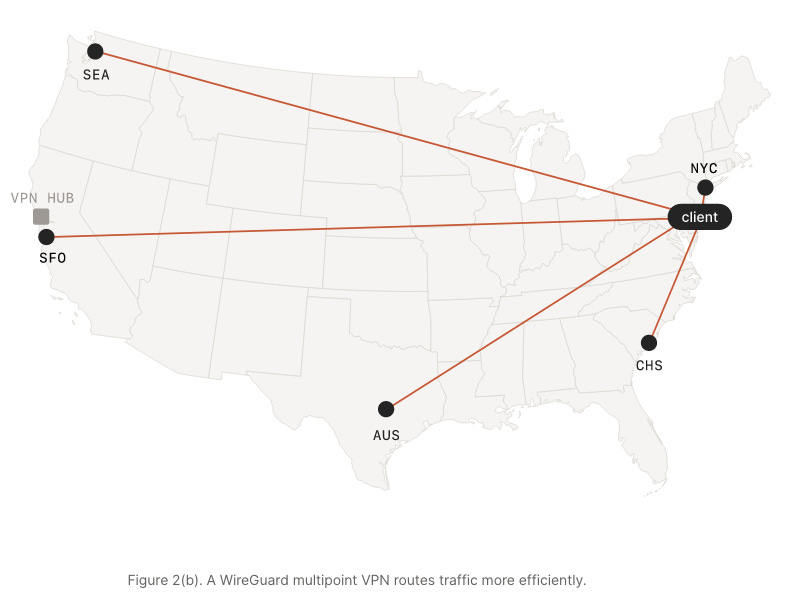
This is accomplished with a lot of NAT Traversal tricks. The Tailscale blog on the subject covers an amazing amount of information and gets super in the weeds. Totally worth the read.
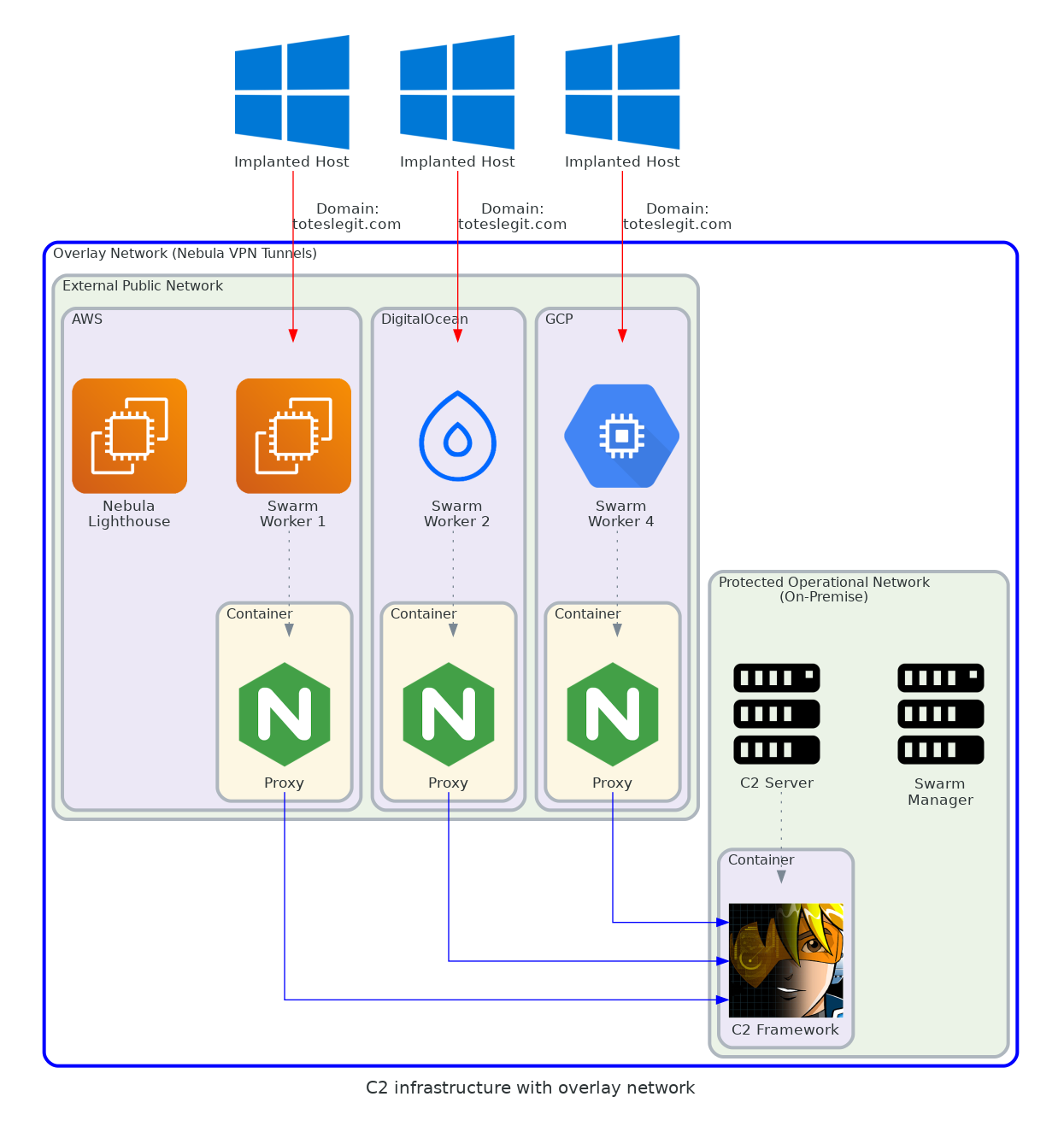
I thought it would be cool to create a more modern version of the CIA’s operational infrastructure combining Docker Swarm and Nebula.
Connecting everything to a Nebula network (e.g. Docker Swarm Worker nodes) allows you to setup Multi or Hybrid Cloud C2 infrastructure with relative ease.
Docker/Containers get rid of any installation issues with C2 frameworks or any software you might need.
All traffic going in, out and inside the C2 infrastructure is encrypted end-to-end thanks to the Nebula tunnels.
We don’t need to expose the Docker Swarm Manager port (TCP 2377) to the internet AND we’ll still be able to directly control all worker nodes (regardless if they’re behind a NAT/firewall) thanks to the Nebula mesh network and it’s support for NAT punching.
Nebula & Tailscale both support the concept of security groups for the traffic passing inside its network. This allows us to add an additional layer of security and lock down traffic flow in the mesh network with relative ease.
Docker Swarm supports service placement constraints, meaning we can tell Docker specifically which host in the Swarm cluster to place our proxies, listening posts, C2 tools and anything else we’d need.
We’re not going to cover creating the infrastructure in the first place. However, below is quick walk-through on how to setup Nebula, Docker Swarm and some example commands and configurations you’ll need if you decide to give this a shot.
For the person who will inevitably ask “Why not Kubernetes instead of Docker Swarm?”: K8s, in my opinion, is overkill for C2 infrastructure and Red Team operations in general. We don’t need high availability and 99% of the other things K8s can do. The complexity K8s brings with it doesn’t payoff in this scenario. Docker swarm is relatively simple and gets things done in a 1/4 of the time.
First we need to create the Nebula certificate authority (CA), which will be the root of trust for our Nebula network and then create Nubla host keys and certificates generated from our CA.
Once you get the latest Nebula release from Github, run the following commands (these were adapted from the Nebula README which you should read in it’s entirety).
# Create the root CA
./nebula-cert ca -name "Legalize Ranch, Inc"
# Create our host keys and certificates
./nebula-cert sign -name "lighthouse" -ip "192.168.100.1/24"
./nebula-cert sign -name "lp1" -ip "192.168.100.2/24" -groups "listening_posts"
./nebula-cert sign -name "lp2" -ip "192.168.100.3/24" -groups "listening_posts"
./nebula-cert sign -name "lp3" -ip "192.168.100.4/24" -groups "listening_posts"
./nebula-cert sign -name "c2" -ip "192.168.100.5/24" -groups "c2_servers"
./nebula-cert sign -name "manager" -ip "192.168.100.6/24" -groups "admin"You should now have a bunch of .crt and .key files in your current directory. The ca.key file is the most sensitive file in this entire setup, keep it in a safe place.
Notice how we also passed the -groups flag when generating the Nebula host keys and certificates. This places those hosts in the specified nebula group(s) which can later be used to define traffic rules in our Nebula network. The -ip flag specifies what IP each host will have in the Nebula network.
So in this example, we’re going to have 6 hosts in our Nebula Network:
192.168.100.1 - Nebula Lighthouse (AWS)
192.168.100.2 - Listening Post 1 (AWS)
192.168.100.3 - Listening Post 2 (GCP)
192.168.100.4 - Listening Post 3 (DigitalOcean)
192.168.100.5 - C2 Server (On-Prem)
192.168.100.6 - Docker Swarm Manager (On-Prem)
Now we need to create the Nebula configuration files for each host. Since we’re using Docker Swarm on top of Nebula, we need to open the following ports *only* between other hosts in the Nebula Network:
Allow access to port 2377 TCP on the Docker Swarm Manager
Allow port 7946 TCP/UDP for container network discovery
Allow port 4789 UDP for the container ingress network
We also need to explicitly allow any ports/services meant to be accessible externally (e.g. port 80/443 on each listening post) through both the cloud service provider firewall rules (e.g. AWS, GCP, DO etc..) and the Nebula configuration file.
I created two Nebula configs for Docker Swarm managers and workers here. I’d highly recommend looking at the example Nebula config file to know what all the options do.
For each host, copy the nebula binary to the host, along with config.yaml from step 5, and the files ca.crt, {host}.crt, and {host}.key from step 4.
DO NOT COPY ca.key TO INDIVIDUAL NODES.
Fire up Nebula on each host:
sudo ./nebula -config /etc/nebula/config.ymlYou should now have all 6 hosts connected to your Nebula network! Huzzah! (you can ping each host to make sure)
Initialize your swarm on the Docker Swarm Manager node specifying the Nebula interface so that Docker Swarm listens and communicates *only* over the Nebula network:
docker swarm init --advertise-addr nebula1 --listen-addr nebula1You will probably want to drain the swarm manager so that docker doesn’t place any containers on it:
docker node update --availability drain <SWARM MANAGER NODE ID>Join all the nodes that are meant to host the c2 servers and listening posts to the swarm, always specifying the Nebula interface so that they only communicate over the Nebula network:
docker swarm join --token <JOIN TOKEN> 192.168.100.6:2377 --advertise-addr nebula1 --listen-addr nebula1Congrats! You now have an end-to-end encrypted, lightweight Multi & Hybrid cloud Docker Swarm deployment!
You can make something available externally no matter which host in the cluster someone makes a request to (taking advantage of Docker Swarm’s ingress routing mesh):
docker service create --name httpd --publish 8080:80 --replicas 1 httpdOr you can make something available *only* on specific nodes in the swarm using placement constraints:
docker node update --label-add type=listening_post <NODE ID>docker service create --name nginx --constraint node.labels.type==listening_post --publish published=80,target=80,mode=host --replicas 1 nginx:alpineHere’s a fancy graph that makes it easier to appreciate what the end result is:
How do you secure the ports open to the public? for example your backend or front end running on swarm? each port is open on each node as the link to routing mesh says...
Are you connecting to ssh server within the nebula network? ssh service starts before the nebula service which probably will fail at some point.
You will end with a public IP where a couple of ports are open on each worker node, so far ssh, 80, 443, nebula, back end... any intrusion from here will have access to your nebula network and the whole set up could be hacked.
Apart of iptables rules, DDos filters etc, and a possible external load balancer... have you done any extra layer of security?
Will consider netmaker which has GUI? (wireguard base)